
数据科学是什么?为什么要学习数据科学?
来不及解释了,先上车 -。-
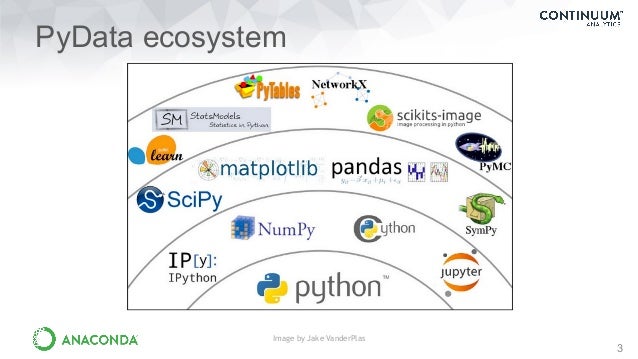
开车之前,为接下来的系列文章做准备,先来罗列一下 Python 科学计算生态中常见的工具包。
IPython
IPython 为 NumPy、SciPy、Pandas、Matplotlib 等包提供一个交互式接口,它本身并不提供科学计算的功能。这些工具组合在一起,形成了可以匹敌如 Matlab、Mathmatic 这些复杂工具的科学计算框架。
不同的工具包,在数据分析的不同阶段各显神通:

NumPy
NumPy 主要提供基础的数组数据结构和矩阵运算。
- 快速高效的多维数组对象
- 可执行向量化计算
- 提供线性代数等矩阵
- 可集成 C 代码
SciPy
基于 NumPy 提供了大量的科学计算算法(信号处理、最优化求解等等),解决标准问题。
- 数值积分和微分方程求解
- 扩展的矩阵计算功能
- 最优化工具
- 概率分布计算和统计函数
- 信号处理函数
Pandas
提供 data frames 数据结构,便于处理真实数据集。
- 易用、高效的数据操作函数库
- 执行 join 以及其他 SQL 类似的功能来重塑数据
- 提供包括 dataframe 在内的数据结构
- 支持各种格式(包括数据库)输入输出
- 支持时间序列
Matplotlib
擅长数据绘图,绘制交互式可视化图像。
- 提供一套和 matlab 相似的命令 API
- 十分适合交互式绘图
- 可以作为绘图控件嵌入 GUI
其他常用工具包
- Seaborn:统计绘图
- StatsModels:统计模型
- scikit-learn:机器学习
- 建立在 NumPy,SciPy 基础上
- 通过统一接口来使用,可以迅速在数据集上实现流行的算法
- 包含许多用于标准机器学习任务的工具,如:聚类、分类和回归等
- Requests:网页数据抓取
- Beautiful Soup:解析网页数据
- Flask:轻量级的 web 框架
- sqlite3:轻量级数据库接口
- Pyspark: Spark 的 Python 接口
- nltk:自然语言处理
- networkx:社交网络分析
- theano:深度学习

